Blokowanie indeksowania strony czyli Robots.txt i Meta robots – porównanie

[ SEOWind.io - pisz treści które rankują się w TOPach ]

W tym artykule poruszymy jak skonstruowany jest plik robots.txt w WordPress czym jest noindex w robots.txt oraz czym różni się od meta robots. Dodatkowo opiszemy co zrobić gdy strona jest zindeksowana, ale zablokowana przez plik robots.txt.

Każdy z posiadaczy strony internetowej chce, aby jej zasoby były jak najlepiej widoczne w wynikach wyszukiwania. Ale co, jeśli chcemy, by konkretne katalogi lub strony, które, np. posiadają poufną, treść były ukryte dla robotów? W tym artykule porównane będą dwie techniki – użycia pliku robots.txt oraz tagów Meta robots. Który z nich i w jaki sposób powinien być stosowany?
Robots.txt oraz Noindex, Index a także Meta Follow i Nofollow dla WordPress
Plik robots.txt informuje roboty wyszukiwarek internetowych, jak mają postępować podczas indeksowania Twojej strony. Domyślnie roboty są bardzo łakome na treść. Chcą zaindeksować jak największą liczbę wysokiej jakości contentu i uważają, że powinny pobierać wszystko, jeśli im tego nie zabroniono. Z biegiem czasu algorytmy stosowane w robotach potrafią odróżnić wartościową (wartą zaindeksowania) treść jednak dla pewności zadbanie o ten aspekt będzie dobrym posunięciem.
Strona zindeksowana ale zablokowana przez plik robots.txt
Ważną częścią tworzenia efektywnego pliku robots.txt jest wcześniejsze przyjęcie odpowiedniej strategii. Oto kilka najczęściej popełnianych błędów:
- umieszczanie dat w adresach URL
- brak kończącego adresy URL katalogów lub zaczynającego wszystkie adresy slah-a (/)
- nazywanie pliku dużymi literami (np. Robots.txt)
- brak pliku na poszczególnych subdomenach serwisu
- używanie pliku jako środka bezpieczeństwa – należy pamiętać, że niektóre z robotów zupełnie ignorują ten plik (np. spamboty)
- stosowanie wielu reguł Disallow/Allow w jednej linii
Uwaga! Należy pamiętać, że jeżeli wykluczymy dla wszystkich robotów (User-agent: *) konkretny katalog lub stronę i dodatkowo zostaną wyszczególnione wyjątki dla poszczególnych robotów (np. Googlebot) wtedy ustawienia globalne będą przez nie zignorowane.
robots.txt noindex

Źródło:www.searchenginejournal.com
Przesłany url zawiera tag „noindex”Internal Link – Best Practices SEO”.
Przykłady zastosowania reguł w pliku robots.txt
User-agent: * Disallow: /katalog/
Zablokowanie katalogu
User-agent: * Disallow: /strona.html
Zablokowanie konkretnej podstrony
User-agent: * Disallow: /*.php$
Zablokowanie wszystkich plików z rozszerzeniem .php (znak $ jako zakończenie)
User-agent: * Disallow: /private*/
Zablokowanie katalogów z nazwą “private” na początku
User-agent: * Disallow: /*?*
Zablokowanie wszystkich adresów zawierających “?”
Google pokazuje w SERP adresy URL wyników wyszukiwania wewnętrznej wyszukiwarki strony. Prowadzi to do strat w Pageranku oraz do znacznego duplikowania treści i jeżeli strona nie posiada dużego page authority zalecane jest zablokowanie robotów w tym obszarze. Jak to zrobić? Zależy to oczywiście od sposobu, w jaki generowane są adresy wyników wyszukiwania na naszej witrynie. Przykładowo:
- Dla WordPress-a będzie to “?s=”
User-agent: * Disallow: /?s=
Dodanie do pliku robots.txt zablokuje Googla w tej strefie
- Dla Drupal-a analogicznie zastosujemy “/search/node/”
Dlaczego Meta robots jest lepszy od robots.txt?
Blokując konkretne adresy URL za pomocą robots.txt poprzez dodanie “Disallow: /strona.html” może spowodować, że będą one dalej pojawiać się w wynikach jako wylistowane adresy URL. Dlatego lepszym rozwiązaniem jest kompletne zablokowanie indeksowania strony poprzez zastosowanie tagu noindex. Kolejnym aspektem jest przekazywanie “mocny strony”, który świetnie opisuje poniższy obrazek:
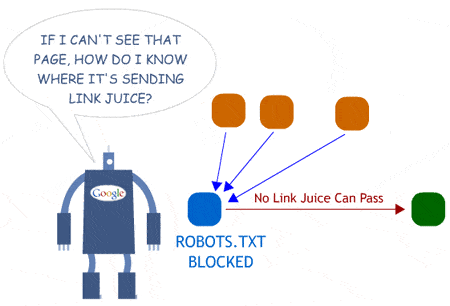
Źródło: moz.com
Stosowanie:
Meta robots noindex
<meta name="robots" content="noindex" />
lub jeśli stosujemy razem z nofollow
<meta name="robots" content="noindex,nofollow" />
Meta robots nofollow
<meta name="robots" content="nofollow" />
lub jeśli stosujemy razem z noindex
<meta name="robots" content="noindex,nofollow" />
| Strona skanowana przez Googlebot? | Info blokowania wyświetlane w indeksie? | Strona przekazuje PageRank? | Ryzyko? Strata? | |
| Robots.txt | NIE |
TAK – jeżeli linkujemy ze strony ten plik może się pojawić jego adres URL. | NIE |
Każdy może wejść w Twój plik robots.txt i wywnioskować, której treści nie chcesz indeksować. Bardzo trzeba uważać na składnię ponieważ wystąpić mogą nieoczekiwane rezultaty. |
| Meta robots noindex tag | TAK | NIE | TAK – mimo tego, że strona nie jest w indeksie to potrafi przekazać swoją moc |
Strony z tagiem noindex dalej są skanowane przez robota Googla nawet jeśli nie występują w wynikach wyszukiwania. Strona, która stosuje noindex+nofollow używana jest do kumulowania PageRanku (nie przekazuje go innym stronom). |
| Meta robots nofollow tag | TAK – jeśli podlinkowana jest z innej strony | TAK – jeśli podlinkowana jest z innej strony | NIE |
Raczej brak. Stosowany wtedy, gdy dążysz do uzyskania pewnego poziomu PageRank i nie chcesz, by strona przekazywała go dalej. |
Tabela podsumowująca działanie dwóch technik blokowania robotów
- Wordcamp 2014 Warszawa – dzień pierwszy - 4 stycznia 2020
- TYPES czyli taxonomies, custom fields i post types w jednym miejscu - 4 stycznia 2020
- Modyfikacje standardowego RSS’a WP - 4 stycznia 2020
- Jak precyzyjniej szukać w Google? [infografika] - 4 stycznia 2020
- Zestawienie blogów o SEO i WordPressie - 4 stycznia 2020
- Funkcje w panelu admina, o których nie warto zapominać - 4 stycznia 2020
- Jak z głową wybrać szablon do WordPressa? - 4 stycznia 2020
- Wtyczki do WP, których nie znasz a powinieneś cz.4 - 4 stycznia 2020
- Kilka ciekawych kawałków kodu cz.1 - 4 stycznia 2020
- Wyświetlanie ilości zasobów WordPressa - 4 stycznia 2020
-
Linki Wewnętrzene i Sematyka
-
-
Budowanie linków
-
Sematyka
-
Budowanie linków nigdy nie było prostrze. Setki możliwości linków za jednym kliknięciem.
-
SEMRush
-
-
Profesjonalna platforma SEO
-
Online
-
SEMrush oferuje rozwiązania dla SEO, PPC, treści, mediów społecznościowych i badań konkurencyjnych.

Admin
test