Jak uruchomić Instant Articles i Google AMP na WordPress ?

[ SEOWind.io - pisz treści które rankują się w TOPach ]
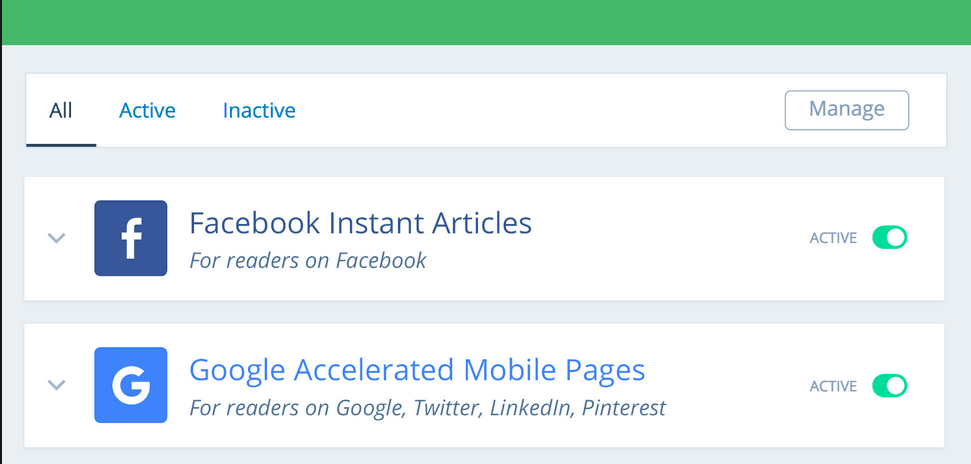
Facebook uruchomił usługę Instant Articles po to, aby użytkownikom czytało się wygodniej i szybciej. Nie jest to złote rozwiązanie, ponieważ użytkownik czytający artykuł ze strony X na platformie Facebook, tak naprawdę nie odwiedza strony docelowej. Niestety wtedy taki użytkownik nie nabija witrynie odwiedzin, nie przejdzie dalej, nie zobaczy paska bocznego, ani polecanych artykułów, które dla niego przygotowaliśmy. Mimo tego niektórzy decydują się na Instant Articles.

Rejestracja na Instant Articles
Rejestracja: https://web.facebook.com/instant_articles/signup?_rdr
Musimy zarejestrować się w usłudze, musimy wybrać witrynę, która nas interesuje. Powinna ona posiadać swój fanpag.
 Zastosujemy wtyczkę Instant Articles for WP. Jest ona prosta i wygodna w użyciu, a więc nikomu nie powinna sprawić większych problemów.
Zastosujemy wtyczkę Instant Articles for WP. Jest ona prosta i wygodna w użyciu, a więc nikomu nie powinna sprawić większych problemów.
Konfiguracja
Następnie powracamy na Facebooka, rozwijamy na dole opcję “Connect your site”. Widzimy tam kod, który należy wkleić w kod motywu przed znacznik “</head>”, następnie poniżej podaje adres naszej witryny.
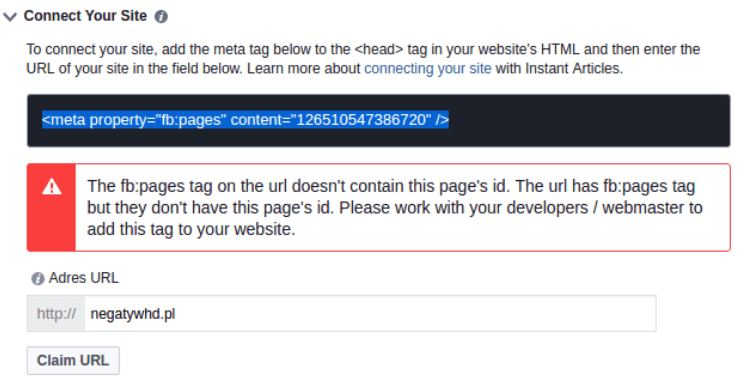
Jeżeli mimo wklejenia kodu, Facebook go nie widzi, polecam wyczyścić cache strony i spróbować np. za 24 godziny.
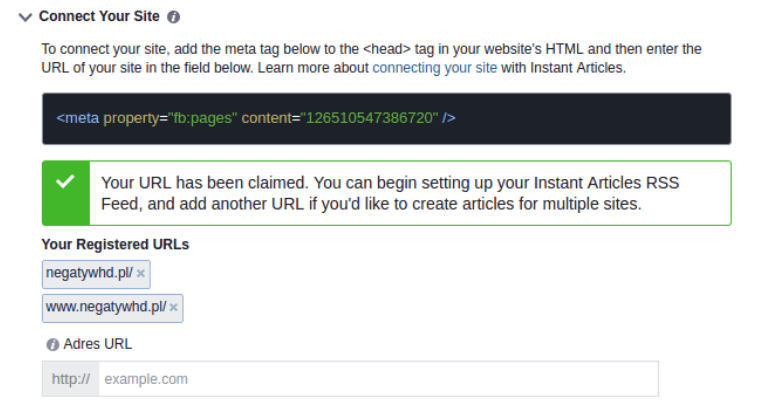
Następnie rozwijamy “Production RSS Feed” i wklejamy tam następujący adres: mojadomena.pl/feed/instant-articles jest to specjalna ścieżka, pod którą Facebook będzie mógł pobrać przygotowane z myślą o nim artykuły z naszej strony.
Następnie znajdujemy opcję STYLING i wgrywamy logo naszej witryny. Logo musi posiadać minimalnie 132 wysokości i 690 szerokości. Warto podczas całego procesu zwracać uwagę na błędy. Pamiętajmy również uzupełnić sekcję “Powiadomienia e-mail”. Kiedy zalogujemy się na WordPressa, na lewo dojdzie nam opcja “Instant Articles”.
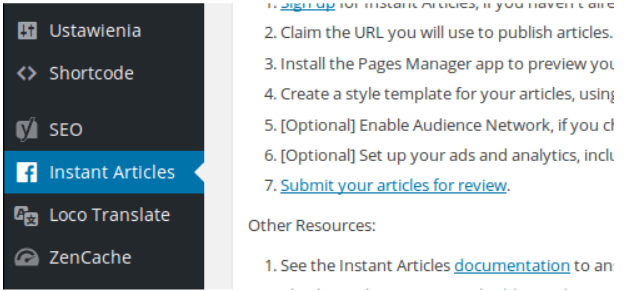
Następnie należy wykonać wszystko, o co nas proszą, aby sekcja “Plugin Activation” wyglądała jak na zrzucie poniżej.
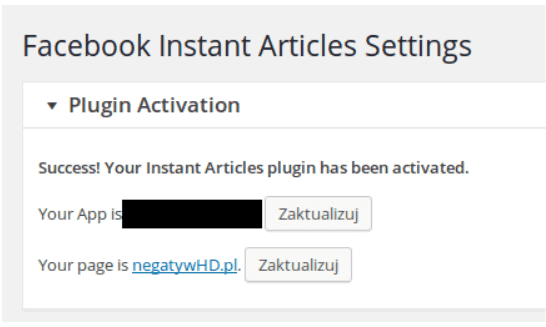
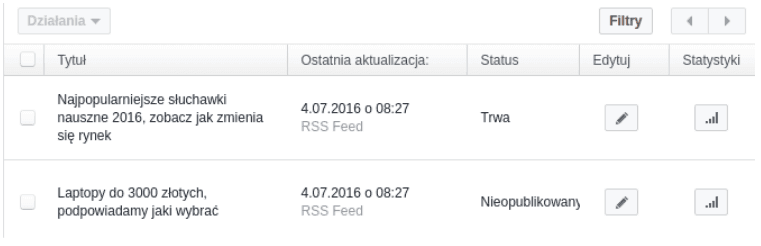
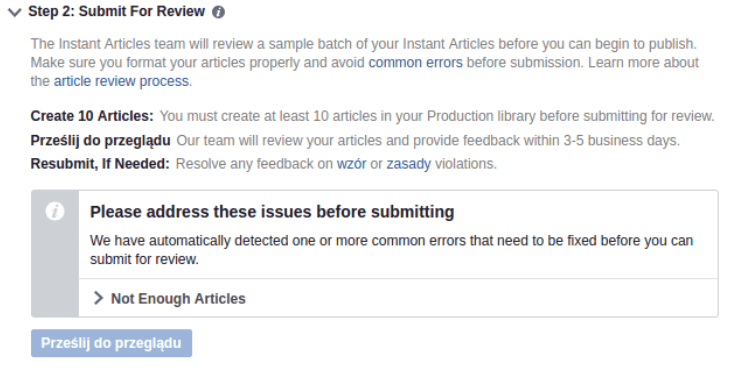 Jak widać, powyżej problem stanowi fakt, że brakuje artykułów, musimy najpierw przesłać 10 sztuk wpisów. Facebook pobiera wpisy ze źródła co godzinę, więc chwilę może to zająć, ale zazwyczaj od razu po dodaniu adresu “Production RSS Feed”. Kiedy tak się stanie i będziemy mieli minimum 10 pobranych wpisów, możemy wysłać je do przeglądu. Takie okienko jak to poniższe świadczy, że za 3 dni możemy spodziewać się informacji o tym, czy nasze artykuły przeszły moderację.
Jak widać, powyżej problem stanowi fakt, że brakuje artykułów, musimy najpierw przesłać 10 sztuk wpisów. Facebook pobiera wpisy ze źródła co godzinę, więc chwilę może to zająć, ale zazwyczaj od razu po dodaniu adresu “Production RSS Feed”. Kiedy tak się stanie i będziemy mieli minimum 10 pobranych wpisów, możemy wysłać je do przeglądu. Takie okienko jak to poniższe świadczy, że za 3 dni możemy spodziewać się informacji o tym, czy nasze artykuły przeszły moderację.
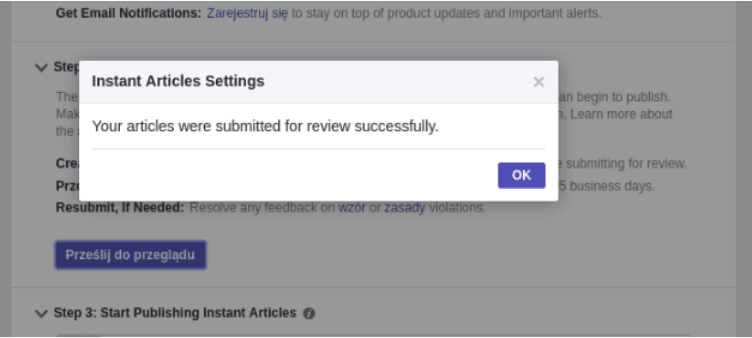
Dopóki tak się nie stanie, nie możemy ich opublikować. Od razu, jak skończy się przegląd poprawności naszych artykułów, przycisk z poniższego zrzutu ekranu stanie się aktywny.
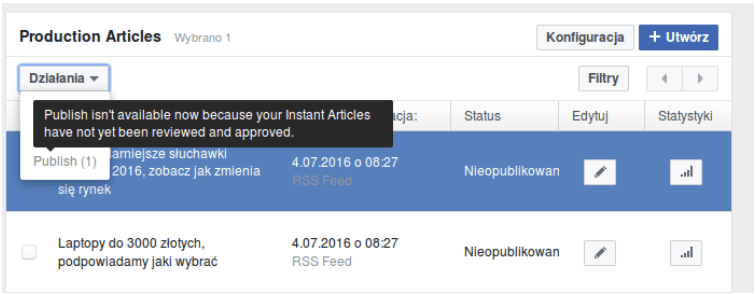
Należy pamiętać, że nawet publikowanie nie odbywa się od razu, trzeba chwilę poczekać.
Rejestracja Google AMP
Accelerated Mobile Pages to nic innego, jak pomysł podobny do Instant Articles (od Facebooka), działa on jednak na nieco innej zasadzie. Przede wszystkim AMP jest projektem open source. Jednak podobnie, jak w projekcie od Facebooka, chodzi o to, aby użytkownik dostał treści szybciej i nie wchodził na naszą stronę, tylko pozostał na platformie danego usługodawcy.
AMP tą właśnie niepozorną wtyczką spowodujemy, że każdy wpis będzie można uruchomić w trybie AMP, czyli z adres:
http://negatywhd.pl/najpopularniejsze-sluchawki-nauszne-2016-zobacz-jak-zmienia-sie-rynek/
tworzy nam się
http://negatywhd.pl/najpopularniejsze-sluchawki-nauszne-2016-zobacz-jak-zmienia-sie-rynek/amp/
więc teraz strona wygląda następująco:

Na wszelki wypadek warto wejść w Ustawienia -> Bezpośrednie Odnośniki i ponownie zapisać zmiany, nic tam nie zmieniając. To niestety nie koniec, teraz musimy sprawić, aby w Google Search Console nasza strona była widoczna.
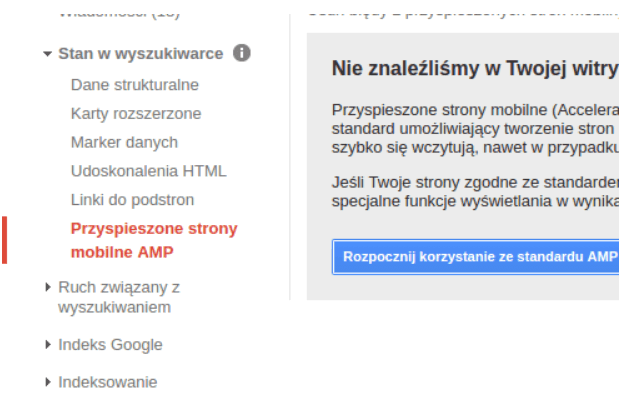 Dodatkowo nasze podstrony nie mogą zwierać żadnych błędów. Czyli, kiedy otworzymy console devtools np. na chrome, nie możemy widzieć tam żadnych błędów, a jedynie taki oto napis:
Dodatkowo nasze podstrony nie mogą zwierać żadnych błędów. Czyli, kiedy otworzymy console devtools np. na chrome, nie możemy widzieć tam żadnych błędów, a jedynie taki oto napis:

W przypadku, gdy będziemy mieli błędy, niestety, ale na pewno wersja mobilna nie zostanie przyjęta przez Google. Warto tutaj skorzystać z narzędzia: http://technicalseo.com/seo-tools/amp/ do testowania AMP.

Jak widać, w moim serwisie nie ma jeszcze AMP CDN, a co to jest? Wesprę się wpisem http://secureglass.net/amp-przyspieszone-strony-mobilne, w którym autor opisuje AMP CDN jako narzędzie dostarczające wszystkich ważnych dokumentów dla AMP. Dzięki niemu wszystko ładowane jest z jednego miejsca, co teoretycznie ma przyspieszyć prędkość ładowania witryny. Na początku działało to niekoniecznie szybciej, o czym świadczy sporo komentarzy w sieci, teraz różnica jest niekiedy spora.
Powyższa metoda pozwala nam dodać wpisy do indeksu, czyli esencję naszej strony. Google powinno po paru dniach zindeksować nasze strony i w zależności od tego, co uważa, wyświetlać je lub też nie wyświetlać.
W ramach podsumowania
Czy to dobrze instalować AMP i Instant Articles? Na to pytanie każdy właściciel strony internetowej powinien odpowiedzieć sobie sam. Na pewno jest to pewien ukłon w stronę użytkownika, w dodatku daje nam szansę na wyświetlanie się w ciekawy sposób w wynikach wyszukiwania i możemy powiedzieć, że nasza witryna jest bardzo nowoczesna.
Czy to jednak dobrze oddawać naszych użytkowników i nasze treści cudzym platformom?
- WordPress i zewnętrzne usługi – krótki przegląd aplikacji, które zepniemy z WordPressem - 4 stycznia 2020
- Pełna pętla WordPress - 4 stycznia 2020
- WordPress i Wcag czy można łatwo spełnić wymagania? - 4 stycznia 2020
- Kanibalizacja słów kluczowych, wstępna diagnoza i naprawa na WordPress - 4 stycznia 2020
- 7 prostych rozwiązań dla WordPress - 4 stycznia 2020
- Google Tag Manager i WordPress – błyskawiczny przepis - 4 stycznia 2020
- Jak uruchomić Instant Articles i Google AMP na WordPress ? - 4 stycznia 2020
- Rejestracja użytkowników na stronie WordPress, kompleksowe rozwiązanie palącego problemu - 4 stycznia 2020
- PIWIK i WordPress, dlaczego warto spojrzeć na te statystyki - 4 stycznia 2020
- Buddypress, czyli społeczność na WordPressie - 4 stycznia 2020
-
Linki Wewnętrzene i Sematyka
-
-
Budowanie linków
-
Sematyka
-
Budowanie linków nigdy nie było prostrze. Setki możliwości linków za jednym kliknięciem.
-
SEMRush
-
-
Profesjonalna platforma SEO
-
Online
-
SEMrush oferuje rozwiązania dla SEO, PPC, treści, mediów społecznościowych i badań konkurencyjnych.
